En el ámbito de los sistemas de gestión de bases de datos (DBMS, por sus siglas en inglés), es fundamental entender la diferencia entre relación y parentesco. Ambos conceptos son esenciales para la organización y el manejo de datos, pero se refieren a aspectos distintos del modelo de datos. Una relación en un DBMS se refiere a una tabla que almacena información sobre un conjunto de entidades, mientras que el parentesco se refiere a la forma en que estas entidades están conectadas entre sí. A continuación, exploraremos en detalle cada uno de estos conceptos, sus características y su importancia en el diseño de bases de datos.
¿Qué es una relación en un DBMS?
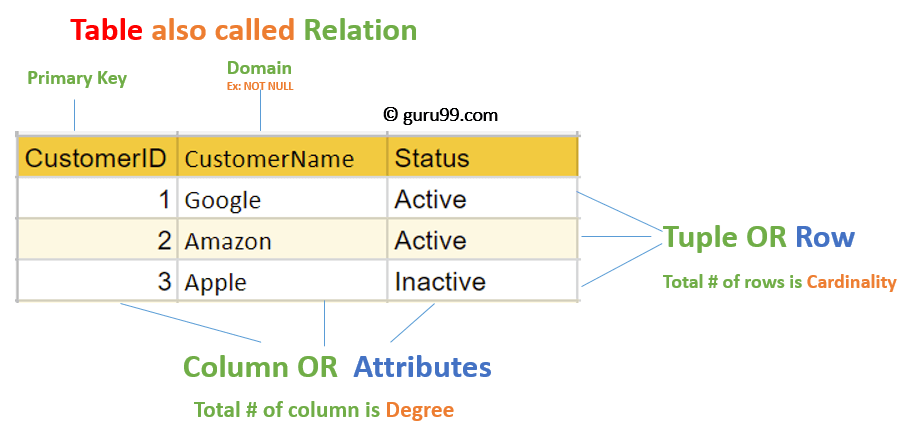
Una relación en un sistema de gestión de bases de datos es fundamentalmente una tabla que organiza datos en filas y columnas. Cada fila de la tabla representa un registro o una instancia de una entidad, mientras que cada columna representa un atributo o característica de esa entidad. Por ejemplo, en una base de datos que almacena información sobre estudiantes, una relación podría ser la tabla «Estudiantes», donde cada fila representa a un estudiante individual y las columnas podrían incluir atributos como nombre, edad, y número de identificación.
Las relaciones son esenciales porque permiten una organización estructurada de los datos, facilitando su acceso y manipulación. Además, cada relación tiene un clave primaria, que es un atributo único que identifica cada registro en la tabla. Esta clave es crucial para garantizar la integridad de los datos y para establecer conexiones entre diferentes relaciones en la base de datos.
 ¿Google Chromecast no funciona con la banda ancha NBN de Telstra? ¿Cómo solucionarlo?
¿Google Chromecast no funciona con la banda ancha NBN de Telstra? ¿Cómo solucionarlo?Además, las relaciones pueden tener claves foráneas, que son atributos que permiten vincular una relación con otra. Esto es importante para establecer un modelo de datos más complejo y para mantener la coherencia de los datos en el sistema. Por ejemplo, si hay una relación «Cursos», la tabla «Estudiantes» podría incluir una clave foránea que apunte a la tabla «Cursos», indicando qué curso está tomando cada estudiante.
Características de las relaciones
- Estructura Tabular: Las relaciones se organizan en un formato de tabla, lo que facilita la comprensión y manipulación de los datos.
- Integridad de los Datos: Las claves primarias y foráneas ayudan a mantener la integridad de los datos en la base de datos.
- Acceso Rápido: Las relaciones permiten realizar consultas eficientes sobre los datos almacenados.
- Flexibilidad: Las relaciones pueden modificarse fácilmente para adaptarse a las necesidades cambiantes de la base de datos.
¿Qué es el parentesco en un DBMS?
El parentesco en un sistema de gestión de bases de datos se refiere a la forma en que las diferentes relaciones están conectadas entre sí. En otras palabras, el parentesco describe las asociaciones y vínculos que existen entre diferentes tablas en una base de datos. Estas conexiones son cruciales para entender cómo interactúan los datos y para realizar consultas complejas que involucren múltiples relaciones.
Existen varios tipos de parentesco, siendo los más comunes el parentesco uno a uno, uno a muchos y muchos a muchos. En una relación de parentesco uno a uno, un registro en una tabla se relaciona con un único registro en otra tabla. Por ejemplo, si cada estudiante tiene un único expediente académico, esta relación sería uno a uno. En el caso de uno a muchos, un registro en una tabla puede estar relacionado con múltiples registros en otra tabla. Por ejemplo, un curso puede tener muchos estudiantes, pero cada estudiante solo puede estar en un curso a la vez. Finalmente, en una relación de muchos a muchos, un registro en una tabla puede estar relacionado con múltiples registros en otra tabla y viceversa. Por ejemplo, los estudiantes pueden estar inscritos en múltiples cursos y cada curso puede tener múltiples estudiantes.
 Diferencia entre espacio de nombres y ensamblado
Diferencia entre espacio de nombres y ensambladoEl entendimiento del parentesco es crucial para el diseño de bases de datos, ya que ayuda a los desarrolladores a estructurar las relaciones de manera que se minimicen la redundancia y la inconsistencia de los datos. Además, permite optimizar el rendimiento de las consultas y facilita la implementación de reglas de negocio que dependen de las interacciones entre diferentes entidades.
Características del parentesco
- Tipos de Relaciones: El parentesco puede clasificarse en uno a uno, uno a muchos y muchos a muchos.
- Conectividad: Permite entender cómo las diferentes entidades se relacionan entre sí.
- Optimización de Consultas: Un buen diseño de parentesco puede mejorar el rendimiento de las consultas.
- Minimización de Redundancia: Un diseño adecuado ayuda a evitar la duplicación de datos.
Diferencias clave entre relación y parentesco
Es importante destacar las diferencias clave entre relación y parentesco en un DBMS. Mientras que una relación se refiere a la estructura tabular que almacena datos, el parentesco se centra en las conexiones y asociaciones entre esas tablas. Esto significa que, aunque ambas son fundamentales para la gestión de datos, abordan diferentes aspectos del sistema.
Otra diferencia importante es que las relaciones están más enfocadas en el almacenamiento y la organización de datos, mientras que el parentesco se preocupa por cómo estos datos interactúan entre sí. Por ejemplo, una relación puede contener información sobre empleados, mientras que el parentesco puede describir cómo esos empleados están organizados en diferentes departamentos o proyectos.
 Diferencia entre INSERT y UPDATE en SQL
Diferencia entre INSERT y UPDATE en SQLAdemás, las relaciones son más estáticas en comparación con el parentesco, que puede cambiar con el tiempo a medida que se agregan o eliminan relaciones entre diferentes entidades. Esto significa que, al diseñar una base de datos, es esencial tener en cuenta tanto las relaciones como el parentesco para crear un modelo de datos que sea eficiente y escalable.
Ejemplos prácticos de relación y parentesco
Para ilustrar la diferencia entre relación y parentesco, consideremos un ejemplo práctico de una base de datos para una biblioteca. En esta base de datos, podríamos tener varias relaciones, como «Libros», «Autores» y «Miembros». Cada una de estas relaciones contendría datos específicos: la tabla «Libros» podría incluir atributos como título, ISBN y género; la tabla «Autores» podría incluir nombre y nacionalidad; y la tabla «Miembros» podría contener información sobre los miembros de la biblioteca.
En este caso, el parentesco se manifestaría en cómo estas relaciones están conectadas. Por ejemplo, un libro puede estar escrito por uno o varios autores, lo que representa una relación de muchos a muchos. Por otro lado, un miembro puede tomar prestados varios libros, lo que también es una relación de muchos a muchos. Para manejar estas conexiones, podríamos crear tablas intermedias, como «Libros_Autores» y «Prestamos», que ayudarían a gestionar las asociaciones de manera efectiva.
Este ejemplo muestra claramente cómo las relaciones y el parentesco trabajan juntos para crear un sistema de gestión de bases de datos cohesivo y funcional. Sin una comprensión clara de ambos conceptos, sería difícil diseñar una base de datos que sea eficiente y capaz de manejar la complejidad de las interacciones entre diferentes entidades.
Importancia de la relación y parentesco en el diseño de bases de datos
El diseño de bases de datos es un proceso crítico que requiere una comprensión profunda de cómo las relaciones y el parentesco afectan el rendimiento y la integridad de los datos. Al establecer relaciones adecuadas entre las tablas, los desarrolladores pueden garantizar que los datos se almacenen de manera eficiente y que se puedan recuperar fácilmente. Además, un diseño de parentesco bien pensado ayuda a prevenir problemas como la inconsistencia de datos y la redundancia.
Un buen diseño de relaciones y parentesco también es crucial para el rendimiento de las consultas. Si las relaciones se establecen correctamente, las consultas se pueden optimizar para que sean más rápidas y eficientes. Esto es especialmente importante en aplicaciones que manejan grandes volúmenes de datos, donde incluso pequeñas mejoras en el rendimiento de las consultas pueden tener un impacto significativo en la experiencia del usuario.
Además, un diseño adecuado de la base de datos facilita la implementación de reglas de negocio. Por ejemplo, si una empresa tiene reglas específicas sobre cómo se deben relacionar los clientes y los pedidos, un diseño de parentesco claro puede ayudar a asegurar que estas reglas se implementen de manera efectiva. Esto no solo mejora la calidad de los datos, sino que también ayuda a garantizar que la base de datos se alinee con los objetivos comerciales de la organización.
Conclusiones sobre relación y parentesco en un DBMS
la diferencia entre relación y parentesco en un sistema de gestión de bases de datos es fundamental para comprender cómo se organizan y gestionan los datos. Mientras que una relación se refiere a la estructura tabular que almacena datos, el parentesco se centra en las conexiones entre esas tablas. Ambos conceptos son esenciales para el diseño efectivo de bases de datos y para garantizar la integridad y eficiencia en la gestión de datos.
Al considerar ambos aspectos en el diseño de una base de datos, los desarrolladores pueden crear sistemas más robustos y escalables que sean capaces de manejar la complejidad de los datos en el mundo real. La comprensión clara de la relación y el parentesco no solo mejora la calidad de los datos, sino que también optimiza el rendimiento y facilita la implementación de reglas de negocio. En última instancia, esto contribuye al éxito general de cualquier aplicación que dependa de una base de datos bien diseñada.