En el ámbito de la tecnología y la gestión de datos, es crucial comprender la diferencia entre el modelo de datos lógico y el modelo de datos físico. Estos modelos son fundamentales para la creación y administración de bases de datos, y cada uno cumple un propósito específico en el ciclo de vida del desarrollo de software. A través de este artículo, exploraremos en detalle las características, diferencias y aplicaciones de cada modelo, para ayudar a los lectores a tener una comprensión clara y sencilla de estos conceptos.
Definición del modelo de datos lógico
El modelo de datos lógico es una representación abstracta de la estructura de una base de datos. Se centra en los requisitos de negocio y en cómo se organizarán los datos sin preocuparse por cómo se almacenarán físicamente. Este modelo es independiente de cualquier sistema de gestión de bases de datos (DBMS) específico, lo que significa que se puede aplicar a diferentes tecnologías. En el modelo lógico, se definen las entidades, sus atributos y las relaciones entre ellas.
Por ejemplo, en un sistema de gestión de estudiantes, las entidades podrían incluir «Estudiante», «Curso» y «Profesor». Cada entidad tendría atributos específicos, como el nombre y la dirección para «Estudiante», o el nombre del curso y el código para «Curso». Las relaciones entre estas entidades también se definen en este modelo, como «un estudiante puede inscribirse en varios cursos» o «un curso puede tener varios estudiantes».
 Diferencia entre red y networking
Diferencia entre red y networkingCaracterísticas del modelo de datos lógico
- Independencia de la tecnología: No depende de un sistema de gestión de bases de datos específico.
- Abstracción: Se centra en cómo se organizan los datos en lugar de cómo se almacenan.
- Enfoque en los requisitos de negocio: Está diseñado para satisfacer las necesidades del negocio y sus procesos.
- Facilidad de comprensión: Es más fácil de entender para los analistas de negocio y otros interesados.
Las características del modelo de datos lógico permiten que diferentes partes interesadas en un proyecto, como analistas, desarrolladores y gerentes, puedan colaborar y comunicarse de manera efectiva. Esto es esencial para asegurar que todos estén alineados con los objetivos y requisitos del proyecto. Al ser un modelo más abstracto, se puede modificar con relativa facilidad en respuesta a cambios en los requisitos del negocio.
Definición del modelo de datos físico
Por otro lado, el modelo de datos físico se refiere a la forma en que los datos se almacenan realmente en el sistema de gestión de bases de datos. Este modelo toma en cuenta factores como la estructura de almacenamiento, el rendimiento y la optimización. En este caso, se definen detalles técnicos como el tipo de datos, los índices, las particiones y las relaciones físicas entre las tablas.
En el mismo ejemplo del sistema de gestión de estudiantes, el modelo físico podría especificar que la tabla «Estudiante» se almacena en un archivo en formato CSV, mientras que la tabla «Curso» se guarda en un formato de base de datos relacional. También se podrían definir índices para acelerar las consultas sobre los estudiantes que están inscritos en un curso específico. Esto es crucial para asegurar que el sistema funcione de manera eficiente y cumpla con las expectativas de rendimiento.
 Diferencia entre error y excepción en C#
Diferencia entre error y excepción en C#Características del modelo de datos físico
- Detallado: Proporciona información específica sobre cómo se almacenan los datos.
- Optimización del rendimiento: Se enfoca en la eficiencia y velocidad de acceso a los datos.
- Dependencia de la tecnología: Está ligado a un sistema de gestión de bases de datos específico.
- Consideraciones de almacenamiento: Toma en cuenta el espacio físico y la estructura de los datos.
El modelo de datos físico es esencial para los administradores de bases de datos y desarrolladores, ya que les permite implementar y gestionar la base de datos de manera efectiva. La elección de la estructura de almacenamiento, los índices y otros detalles técnicos puede tener un impacto significativo en el rendimiento general del sistema. Por lo tanto, es fundamental que los profesionales de la tecnología comprendan bien este modelo para optimizar el acceso y la gestión de los datos.
Diferencias clave entre el modelo lógico y el modelo físico
Las diferencias entre el modelo de datos lógico y el modelo de datos físico son fundamentales para entender cómo se gestionan y utilizan los datos en un sistema. La primera diferencia notable es la abstracción. El modelo lógico es más abstracto y se centra en las necesidades del negocio, mientras que el modelo físico se ocupa de la implementación real de esos datos en un sistema de gestión de bases de datos.
Otra diferencia importante es la independencia tecnológica. El modelo lógico es independiente de cualquier tecnología específica, lo que permite su uso en diferentes plataformas. En contraste, el modelo físico está directamente relacionado con una tecnología particular, lo que significa que las decisiones sobre cómo almacenar y acceder a los datos pueden variar significativamente entre diferentes sistemas de gestión de bases de datos.
 Diferencia entre Redis y Memcached
Diferencia entre Redis y MemcachedComparación directa
- Modelo Lógico: Abstracción, independencia tecnológica, enfoque en requisitos de negocio.
- Modelo Físico: Detalles técnicos, dependiente de tecnología, optimización del rendimiento.
Además, el modelo lógico se ocupa de las relaciones y entidades a un nivel conceptual, mientras que el modelo físico se enfoca en cómo esas relaciones se implementan en términos de tablas y campos en una base de datos. Esto implica que, aunque ambos modelos son necesarios y complementarios, sirven a diferentes propósitos y requieren diferentes enfoques y habilidades para su desarrollo y mantenimiento.
Importancia de cada modelo en el desarrollo de bases de datos
Ambos modelos son esenciales en el desarrollo de bases de datos, pero cumplen funciones diferentes. El modelo lógico es crucial en las primeras etapas del desarrollo, donde se identifican y definen los requisitos de negocio. Esto permite que los analistas y diseñadores de bases de datos tengan una visión clara de lo que se necesita antes de que se realicen decisiones técnicas.
Por otro lado, el modelo físico es fundamental en la fase de implementación. Una vez que se ha definido la estructura lógica, el equipo de desarrollo necesita traducir esa estructura a un formato que pueda ser comprendido y manejado por un sistema de gestión de bases de datos específico. Esto incluye la creación de tablas, la definición de índices y la configuración de relaciones físicas entre los datos.
Fases del desarrollo de bases de datos
- Fase de análisis: Se utiliza el modelo lógico para identificar necesidades y requisitos.
- Fase de diseño: Se desarrolla el modelo lógico en un modelo físico para su implementación.
- Fase de implementación: Se crean las estructuras de datos físicas y se configuran en el DBMS.
- Fase de mantenimiento: Se revisan y optimizan ambos modelos según sea necesario.
La interacción entre el modelo lógico y el modelo físico es un proceso continuo. A medida que los requisitos del negocio cambian o evolucionan, es posible que se necesiten ajustes tanto en el modelo lógico como en el físico. Por lo tanto, los equipos de desarrollo deben estar preparados para revisar y actualizar ambos modelos a lo largo del ciclo de vida de la base de datos.
Ejemplo práctico de modelos de datos
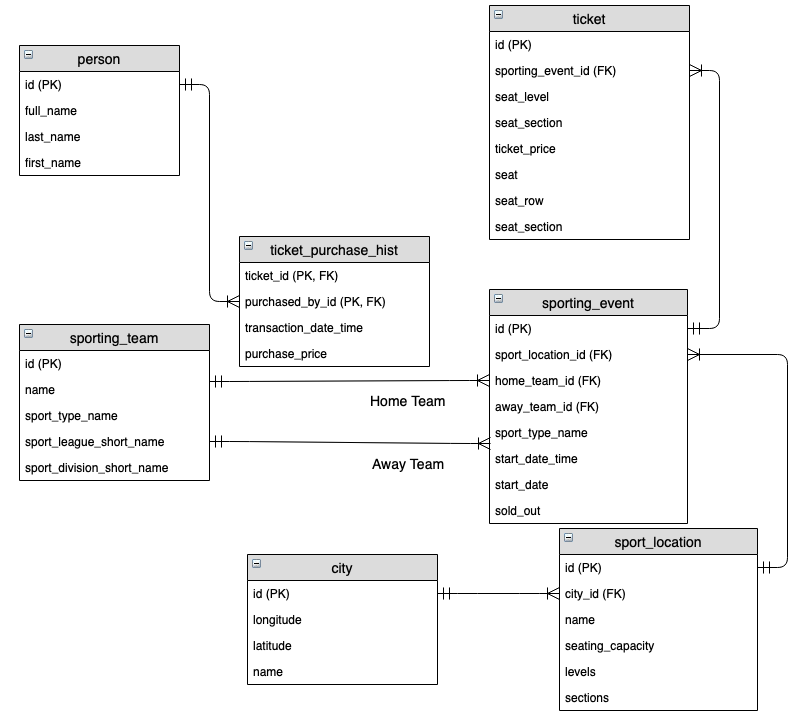
Para ilustrar la diferencia entre el modelo lógico y el modelo físico, consideremos un ejemplo práctico en el contexto de una tienda en línea. En el modelo lógico, podríamos tener las entidades «Cliente», «Pedido» y «Producto». Cada entidad tendría atributos como el nombre del cliente, la fecha del pedido y el precio del producto. Además, las relaciones podrían indicar que un cliente puede realizar múltiples pedidos y que un pedido puede contener varios productos.
En el modelo físico, esta estructura lógica se implementaría en una base de datos. Por ejemplo, la entidad «Cliente» podría convertirse en una tabla con columnas como «ID_Cliente», «Nombre», «Email», etc. Los índices podrían crearse en el campo «Email» para optimizar las búsquedas, y las relaciones entre las tablas se definirían utilizando claves foráneas. Esto demuestra cómo la misma estructura de datos puede verse de manera diferente en cada modelo.
Visualización de modelos
- Modelo Lógico: Entidades, atributos, relaciones.
- Modelo Físico: Tablas, columnas, índices, claves foráneas.
Este ejemplo muestra claramente cómo los modelos lógico y físico interactúan y se complementan. Mientras que el modelo lógico ayuda a definir la estructura de los datos desde una perspectiva empresarial, el modelo físico se encarga de la implementación técnica que permite que esos datos sean almacenados y gestionados de manera eficiente.
Herramientas para modelar datos
Existen diversas herramientas disponibles para ayudar a los desarrolladores y analistas a crear y gestionar modelos de datos lógicos y físicos. Estas herramientas permiten representar gráficamente las entidades, relaciones y atributos, lo que facilita la comprensión y el diseño de bases de datos. Algunas de las herramientas más populares incluyen ER/Studio, MySQL Workbench, y Oracle SQL Developer.
Estas herramientas permiten a los usuarios crear diagramas de entidad-relación (ER), que son visualizaciones gráficas que muestran cómo se relacionan las diferentes entidades dentro de un modelo de datos. Además, muchas de estas herramientas ofrecen funcionalidades para generar automáticamente el modelo físico a partir del modelo lógico, lo que ahorra tiempo y reduce la posibilidad de errores en la implementación.
Características de las herramientas de modelado
- Visualización gráfica: Permiten crear diagramas claros y comprensibles.
- Generación automática: Facilitan la creación del modelo físico a partir del modelo lógico.
- Colaboración: Posibilitan el trabajo en equipo y la revisión de modelos.
- Documentación: Ayudan a documentar los modelos de datos para futuras referencias.
La elección de la herramienta adecuada dependerá de las necesidades específicas del proyecto y de las preferencias del equipo de desarrollo. Sin embargo, el uso de estas herramientas puede mejorar significativamente la eficiencia y la precisión en el diseño y la implementación de bases de datos, lo que es esencial para el éxito de cualquier proyecto que dependa de datos.
Retos en el modelado de datos
El proceso de modelado de datos, tanto lógico como físico, no está exento de desafíos. Uno de los principales retos es garantizar que el modelo lógico refleje con precisión los requisitos del negocio. A menudo, los requisitos pueden ser ambiguos o cambiar con el tiempo, lo que puede llevar a un modelo lógico que no se alinea bien con la implementación física.
Otro reto importante es la optimización del modelo físico. Al implementar un modelo físico, es crucial considerar factores como el rendimiento y la escalabilidad. Esto puede implicar tomar decisiones difíciles sobre la normalización de datos, la creación de índices y la estructura de almacenamiento. Las decisiones incorrectas en esta fase pueden llevar a problemas de rendimiento que pueden ser costosos y difíciles de resolver más adelante.
Desafíos comunes
- Ambigüedad en los requisitos: Dificultad para definir un modelo lógico preciso.
- Decisiones de optimización: Elegir la mejor estructura de datos y almacenamiento.
- Cambios en el negocio: Necesidad de adaptar los modelos a nuevos requisitos.
- Integración de sistemas: Dificultades para alinear diferentes modelos en sistemas existentes.
Superar estos retos requiere una colaboración efectiva entre los equipos de negocio y de tecnología, así como una comunicación clara y continua. Además, es importante realizar pruebas y revisiones periódicas de los modelos para asegurar que sigan siendo relevantes y efectivos a medida que el negocio y la tecnología evolucionan.
Futuro del modelado de datos
El modelado de datos está en constante evolución, impulsado por avances en la tecnología y cambios en las necesidades empresariales. Con el auge de tecnologías como big data, inteligencia artificial y cloud computing, los modelos de datos deben adaptarse para manejar volúmenes masivos de información y requerimientos de procesamiento en tiempo real.
Además, la tendencia hacia la integración de datos y el uso de arquitecturas de microservicios está cambiando la forma en que se diseñan y gestionan las bases de datos. Esto significa que los modelos de datos deben ser más flexibles y capaces de adaptarse a entornos en constante cambio. Los enfoques modernos como el modelado ágil y el modelado de datos en tiempo real están ganando popularidad, permitiendo a las organizaciones responder más rápidamente a las necesidades del mercado.
Tendencias futuras
- Big Data: Manejo de grandes volúmenes de datos no estructurados.
- Inteligencia Artificial: Uso de modelos predictivos y análisis avanzados.
- Integración en la nube: Modelos adaptados para arquitecturas de nube.
- Modelado ágil: Respuestas rápidas a cambios en los requisitos del negocio.
A medida que el entorno tecnológico continúa evolucionando, el modelado de datos se convertirá en un aspecto aún más crítico para las organizaciones que buscan aprovechar al máximo sus datos. La capacidad de crear modelos lógicos y físicos efectivos y adaptables será fundamental para el éxito en un mundo cada vez más impulsado por los datos.