
En el mundo de la programación, especialmente en Java, es esencial comprender las diferentes estructuras de datos que están disponibles. Dos de las más utilizadas son HashMap y LinkedHashMap. Ambas son implementaciones de la interfaz Map y permiten almacenar pares de clave-valor. Sin embargo, existen diferencias clave entre ellas que pueden influir en la elección de cuál usar en un determinado contexto. En este artículo, exploraremos estas diferencias en detalle, analizando sus características, ventajas y desventajas, así como sus casos de uso específicos.
Diferencias clave entre HashMap y LinkedHashMap
Una de las diferencias más notables entre HashMap y LinkedHashMap es la forma en que almacenan los elementos. Mientras que HashMap no garantiza ningún orden específico en la iteración de sus elementos, LinkedHashMap mantiene un orden de inserción. Esto significa que si insertamos elementos en un LinkedHashMap, cuando iteremos sobre él, los elementos aparecerán en el mismo orden en que fueron añadidos. Esta característica puede ser crucial en aplicaciones donde el orden de los elementos es importante.
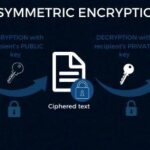 Diferencia entre cifrado simétrico y asimétrico
Diferencia entre cifrado simétrico y asimétricoAdemás, LinkedHashMap utiliza una lista doblemente enlazada para mantener el orden de inserción, lo que añade una sobrecarga adicional en comparación con HashMap, que utiliza una tabla hash. Esta sobrecarga puede hacer que LinkedHashMap sea un poco más lento en operaciones de inserción y eliminación en comparación con HashMap. Sin embargo, el beneficio es que ofrece una iteración predecible, lo que puede ser ventajoso en muchos escenarios.
Rendimiento y eficiencia
En términos de rendimiento, HashMap suele ser más eficiente en operaciones de búsqueda, inserción y eliminación. Esto se debe a que las operaciones en un HashMap tienen un tiempo promedio de complejidad de O(1). Sin embargo, esta eficiencia puede verse afectada si hay colisiones en la tabla hash, lo que podría llevar a un rendimiento O(n) en el peor de los casos. A pesar de esto, en la mayoría de las situaciones, HashMap es preferido por su velocidad.
Por otro lado, LinkedHashMap tiene un rendimiento ligeramente inferior debido a la necesidad de mantener la lista de nodos para conservar el orden de inserción. Esto significa que aunque las operaciones básicas como la búsqueda y la inserción aún tienen un tiempo de complejidad de O(1), el costo adicional de mantener la lista puede hacer que sea un poco más lento. Sin embargo, el rendimiento de LinkedHashMap sigue siendo bastante aceptable y, en muchos casos, el orden de los elementos puede justificar la ligera disminución en la velocidad.
 Diferencia entre scanf y getchar
Diferencia entre scanf y getcharUso de memoria
La memoria también es un aspecto importante a considerar al elegir entre HashMap y LinkedHashMap. Como se mencionó anteriormente, LinkedHashMap mantiene una lista doblemente enlazada que consume más memoria en comparación con HashMap, que solo utiliza una tabla hash. Esta diferencia en el uso de memoria puede ser significativa en aplicaciones donde se manejan grandes volúmenes de datos. Si el uso de memoria es una preocupación crítica, HashMap podría ser la opción más adecuada.
Sin embargo, el uso de memoria también depende del tamaño de los elementos que se están almacenando. Si los elementos son relativamente pequeños y el orden de inserción es importante, la sobrecarga de memoria de LinkedHashMap puede ser aceptable. Por lo tanto, es importante evaluar el contexto de la aplicación y decidir cuál es el enfoque más adecuado según las necesidades específicas.
Orden de los elementos
El orden de los elementos es uno de los aspectos más importantes que distingue a HashMap de LinkedHashMap. Como se mencionó anteriormente, HashMap no garantiza el orden de los elementos. Esto significa que, si se itera sobre un HashMap, el orden de los elementos puede ser diferente al orden en que fueron añadidos. Esto puede ser problemático en situaciones donde se requiere un orden específico, como en la visualización de datos o en la presentación de resultados al usuario.
 Diferencia entre cifrado y descifrado
Diferencia entre cifrado y descifradoEn contraste, LinkedHashMap mantiene el orden de inserción, lo que lo hace ideal para situaciones donde el orden es crucial. Esto es especialmente útil en aplicaciones que requieren una presentación ordenada de datos, como listas de usuarios, registros o cualquier tipo de datos donde el orden de llegada es significativo. Esta característica le otorga a LinkedHashMap una ventaja considerable en términos de usabilidad en ciertos contextos.
Iteración sobre elementos
La forma en que se itera sobre los elementos de una colección es otro punto a considerar. En un HashMap, aunque puedes iterar sobre las claves, valores o entradas, el orden en que se obtienen no es predecible. Esto puede ser un inconveniente en ciertas aplicaciones donde el orden de los elementos es importante. Por otro lado, LinkedHashMap ofrece una iteración predecible que sigue el orden de inserción, lo que facilita el trabajo con los datos cuando se requiere un orden específico.
La iteración sobre un LinkedHashMap se puede realizar utilizando un bucle for-each, lo que proporciona una forma sencilla de acceder a cada elemento en el orden en que fueron añadidos. Esto es especialmente útil en escenarios donde necesitas mostrar datos en una interfaz de usuario o cuando necesitas realizar operaciones en un conjunto de datos en un orden específico. Esta característica de LinkedHashMap lo convierte en una opción preferida en muchas aplicaciones de desarrollo.
Uso en aplicaciones específicas
La elección entre HashMap y LinkedHashMap puede depender del tipo de aplicación que estés desarrollando. Por ejemplo, si estás creando una aplicación que necesita almacenar datos temporales donde el orden no es importante, un HashMap sería una excelente opción. Su eficiencia en términos de velocidad y uso de memoria lo convierte en una opción ideal para almacenar datos donde el rendimiento es clave.
Por otro lado, si estás desarrollando una aplicación que necesita mostrar datos en un orden específico, como una lista de contactos o un historial de navegación, un LinkedHashMap sería más adecuado. La capacidad de LinkedHashMap para mantener el orden de inserción asegura que los datos se presenten de manera coherente y predecible, lo que mejora la experiencia del usuario.
Ejemplos prácticos
Para entender mejor las diferencias entre HashMap y LinkedHashMap, consideremos algunos ejemplos prácticos. Supongamos que estamos desarrollando una aplicación de gestión de contactos. Si utilizamos un HashMap para almacenar los contactos, podríamos añadir contactos de la siguiente manera:
- contactos.put(«Juan», «123456789»);
- contactos.put(«Ana», «987654321»);
- contactos.put(«Pedro», «456789123»);
Al iterar sobre el HashMap, el orden de los contactos podría no ser el mismo que el orden en que fueron añadidos, lo que podría resultar confuso para el usuario. En cambio, si utilizamos un LinkedHashMap, el mismo código produciría un resultado donde los contactos se presentan en el orden en que fueron añadidos, lo que es mucho más intuitivo.
Conclusiones sobre el uso de HashMap y LinkedHashMap
Al final del día, la elección entre HashMap y LinkedHashMap depende de los requisitos específicos de tu aplicación. Si necesitas un rendimiento rápido y no te importa el orden de los elementos, HashMap es la opción correcta. Sin embargo, si el orden de inserción es importante y puedes aceptar un ligero costo en rendimiento y uso de memoria, LinkedHashMap es la mejor opción.
En resumen, ambas estructuras de datos tienen sus ventajas y desventajas. La clave está en entender las necesidades de tu aplicación y elegir la estructura de datos que mejor se adapte a esos requisitos. A medida que sigas desarrollando tus habilidades en programación, te volverás más competente en la selección de las estructuras de datos adecuadas para cada situación.