
Cuando se trata de manejar grandes volúmenes de datos, especialmente en el ecosistema de Apache Hadoop, dos herramientas populares que suelen mencionarse son Hive e Impala. Ambas están diseñadas para facilitar el análisis de datos, pero tienen diferencias clave en su funcionamiento, rendimiento y uso. En este artículo, exploraremos en profundidad estas diferencias, para que puedas entender cuál de estas herramientas puede ser la más adecuada para tus necesidades de análisis de datos.
¿Qué es Hive?
Apache Hive es una herramienta de data warehousing que permite a los usuarios realizar consultas sobre grandes conjuntos de datos almacenados en Hadoop. Se basa en un modelo de datos similar a SQL, lo que facilita que los analistas y desarrolladores que están familiarizados con SQL puedan utilizarlo. Hive traduce las consultas en tareas de MapReduce, lo que significa que puede manejar grandes volúmenes de datos, pero también puede experimentar cierta latencia en la ejecución de consultas debido a la naturaleza de MapReduce.
Una de las características más destacadas de Hive es su capacidad para manejar datos estructurados y semi-estructurados. Esto lo hace ideal para empresas que necesitan analizar datos de diversas fuentes. La interfaz de Hive permite a los usuarios definir tablas, particiones y esquemas de manera sencilla, lo que facilita la organización de datos. Además, Hive proporciona un lenguaje de consulta llamado HiveQL, que es similar a SQL, lo que lo hace accesible para quienes ya están familiarizados con este último.
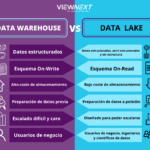 Diferencia entre un lago de datos y un almacén de datos
Diferencia entre un lago de datos y un almacén de datos¿Qué es Impala?
Apache Impala, por otro lado, es un motor de consulta SQL en tiempo real que permite a los usuarios realizar análisis de datos de forma rápida y eficiente. A diferencia de Hive, Impala no utiliza MapReduce para ejecutar consultas. En su lugar, utiliza un enfoque de ejecución de consultas en memoria, lo que significa que puede devolver resultados mucho más rápidamente. Esto lo hace especialmente útil para aplicaciones que requieren análisis en tiempo real y respuestas rápidas a consultas.
Impala también es compatible con SQL, lo que permite a los usuarios ejecutar consultas complejas sobre datos almacenados en HDFS (Hadoop Distributed File System) y HBase. Al igual que Hive, Impala puede manejar datos estructurados y semi-estructurados, pero su principal ventaja radica en la velocidad de ejecución. Esto lo convierte en una opción popular para empresas que necesitan obtener información de sus datos en tiempo real.
Comparación de rendimiento
El rendimiento es una de las diferencias más notables entre Hive e Impala. Como se mencionó anteriormente, Hive utiliza MapReduce para ejecutar consultas, lo que puede llevar tiempo, especialmente para consultas complejas. Por otro lado, Impala está diseñado para ser rápido y eficiente, permitiendo la ejecución de consultas en tiempo real. Esto significa que los usuarios pueden obtener resultados mucho más rápidamente con Impala, lo que es crucial para aplicaciones que requieren respuestas inmediatas.
 Diferencia entre un lenguaje de marcado y un lenguaje de programación
Diferencia entre un lenguaje de marcado y un lenguaje de programaciónUna comparación común entre ambas herramientas es la latencia en la ejecución de consultas. Mientras que Hive puede tardar varios minutos en devolver resultados, especialmente para consultas complejas, Impala puede proporcionar respuestas en segundos o incluso milisegundos. Esto se debe a su arquitectura optimizada y al uso de ejecución en memoria, que minimiza el tiempo de espera para los usuarios.
Ventajas del rendimiento de Impala
- Consultas en tiempo real: Impala permite a los usuarios ejecutar consultas y obtener resultados casi instantáneamente.
- Optimización en memoria: La ejecución de consultas en memoria mejora la velocidad de procesamiento.
- Menor latencia: Impala puede manejar consultas complejas con menor tiempo de espera en comparación con Hive.
Modelo de datos y esquema
Ambas herramientas manejan datos estructurados y semi-estructurados, pero su enfoque hacia el modelo de datos y el esquema es diferente. Hive utiliza un enfoque más tradicional, donde los usuarios definen esquemas y tablas antes de cargar los datos. Esto permite una mayor organización, pero también puede hacer que el proceso sea más lento, ya que se requiere un diseño cuidadoso del esquema antes de comenzar a trabajar con los datos.
En contraste, Impala permite una mayor flexibilidad en la forma en que se pueden manejar los datos. Los usuarios pueden realizar consultas sobre datos sin necesidad de definir un esquema rígido de antemano. Esto significa que puedes cargar datos y comenzar a consultarlos de inmediato, lo que puede ser una ventaja en entornos donde los datos cambian con frecuencia o se reciben de diversas fuentes.
 Diferencia entre un lenguaje de script y un lenguaje de programación
Diferencia entre un lenguaje de script y un lenguaje de programaciónAspectos del modelo de datos en Hive
- Definición de esquema: Requiere que los usuarios definan el esquema antes de cargar los datos.
- Particionamiento: Permite el particionamiento de datos para mejorar el rendimiento de las consultas.
- Organización de datos: Proporciona una estructura organizada para el almacenamiento de datos.
Aspectos del modelo de datos en Impala
- Flexibilidad: Permite consultas sin necesidad de un esquema definido previamente.
- Soporte para datos variados: Puede manejar datos de diferentes formatos y fuentes sin complicaciones.
- Rapidez en la consulta: Facilita el análisis de datos en tiempo real sin esperar a la definición de un esquema.
Facilidad de uso y aprendizaje
La facilidad de uso y el aprendizaje son factores importantes a considerar al elegir entre Hive e Impala. Hive, al ser similar a SQL, es bastante accesible para aquellos que ya tienen experiencia con bases de datos relacionales. Su sintaxis, conocida como HiveQL, permite a los usuarios ejecutar consultas de manera intuitiva, lo que facilita su adopción en equipos que ya están familiarizados con SQL.
Por otro lado, aunque Impala también utiliza SQL, su enfoque en la ejecución en tiempo real y sus características avanzadas pueden requerir un aprendizaje adicional. Sin embargo, muchos usuarios encuentran que la rapidez y la eficiencia de Impala valen la pena el esfuerzo de aprendizaje. La comunidad de usuarios de Impala también ha crecido, lo que significa que hay recursos y documentación disponibles para ayudar a los nuevos usuarios a familiarizarse con la herramienta.
Ventajas de la facilidad de uso en Hive
- Interfaz intuitiva: La sintaxis similar a SQL hace que sea fácil de aprender para los analistas de datos.
- Documentación abundante: Hay muchos recursos disponibles para ayudar a los nuevos usuarios a comenzar.
- Comunidad activa: Hive tiene una comunidad activa que proporciona soporte y comparte conocimientos.
Ventajas de la facilidad de uso en Impala
- Rápido aprendizaje: Los usuarios con experiencia en SQL pueden adaptarse rápidamente a Impala.
- Recursos en línea: Existen muchos tutoriales y documentación que ayudan a los nuevos usuarios.
- Comunidad creciente: La comunidad de usuarios de Impala está en expansión, lo que facilita el acceso a soporte.
Integración con otros sistemas
La integración con otros sistemas es otro aspecto importante a considerar. Hive es conocido por su capacidad para integrarse con una variedad de herramientas y plataformas dentro del ecosistema Hadoop. Esto incluye herramientas de visualización, sistemas de almacenamiento de datos y otros componentes de análisis. Esta integración facilita el trabajo con datos desde diferentes fuentes y permite a los usuarios crear flujos de trabajo más completos.
Impala también ofrece opciones de integración, pero su enfoque está más centrado en proporcionar consultas rápidas y eficientes. Esto significa que, aunque puede integrarse con otras herramientas, su principal fortaleza radica en la ejecución de consultas rápidas sobre datos almacenados en Hadoop. Las empresas que utilizan Impala a menudo lo combinan con otras herramientas de análisis y visualización para obtener el máximo rendimiento.
Integración de Hive con otros sistemas
- Compatibilidad con Hadoop: Se integra perfectamente con el ecosistema Hadoop.
- Herramientas de visualización: Puede conectarse a herramientas de visualización de datos como Tableau y Qlik.
- Soporte para múltiples formatos de datos: Puede trabajar con datos en diferentes formatos como Avro, Parquet y ORC.
Integración de Impala con otros sistemas
- Optimización para consultas rápidas: Se centra en ejecutar consultas de manera eficiente en datos almacenados en Hadoop.
- Interoperabilidad: Puede integrarse con otras herramientas de análisis para mejorar el rendimiento.
- Conexiones con herramientas de BI: Soporta conexiones con herramientas de inteligencia de negocios para facilitar el análisis.
Casos de uso
Cuando se trata de casos de uso, tanto Hive como Impala tienen sus propias aplicaciones. Hive es ideal para situaciones donde se necesita realizar análisis complejos sobre grandes volúmenes de datos. Por ejemplo, empresas que requieren informes detallados y análisis de datos históricos pueden beneficiarse enormemente de las capacidades de Hive. Su enfoque en la organización de datos y la estructura de esquemas permite un análisis profundo y detallado.
Por otro lado, Impala es más adecuado para aplicaciones que requieren respuestas rápidas a consultas en tiempo real. Esto lo convierte en una excelente opción para empresas que necesitan monitorear datos en tiempo real, como las que operan en el sector financiero o en el comercio electrónico. La velocidad de Impala permite a estas empresas tomar decisiones informadas basadas en datos actuales y relevantes.
Ejemplos de casos de uso para Hive
- Análisis de datos históricos: Ideal para informes y análisis de tendencias a lo largo del tiempo.
- Data warehousing: Útil para almacenar grandes volúmenes de datos de diversas fuentes.
- Consultas complejas: Permite realizar consultas SQL complejas para obtener insights profundos.
Ejemplos de casos de uso para Impala
- Monitoreo en tiempo real: Perfecto para aplicaciones que requieren análisis instantáneo de datos.
- Informes interactivos: Ideal para generar informes rápidos y visualizaciones de datos en tiempo real.
- Analítica de negocio: Utilizado en el sector financiero para decisiones basadas en datos actuales.
Costos y licencias
En cuanto a costos y licencias, tanto Hive como Impala son herramientas de código abierto, lo que significa que no hay costos de licencia asociados a su uso. Sin embargo, las empresas que decidan implementar estas herramientas pueden incurrir en costos relacionados con la infraestructura, el almacenamiento y el mantenimiento. Además, el soporte técnico y la capacitación para los empleados pueden agregar costos adicionales.
Es importante que las empresas evalúen estos costos al considerar la implementación de Hive o Impala. Aunque ambas herramientas son gratuitas, la inversión en hardware, soporte y capacitación puede variar significativamente. Las empresas deben considerar sus necesidades específicas y su presupuesto al elegir entre Hive e Impala.
Costos asociados a Hive
- Infraestructura: Requiere servidores y almacenamiento para manejar grandes volúmenes de datos.
- Soporte técnico: Puede ser necesario contratar soporte externo o capacitación para el personal.
- Mantenimiento: Los costos de mantenimiento de la infraestructura pueden acumularse con el tiempo.
Costos asociados a Impala
- Infraestructura: Similar a Hive, se requieren recursos para la implementación y el mantenimiento.
- Capacitación: Puede ser necesario invertir en capacitación para que los empleados se familiaricen con la herramienta.
- Integración: Los costos de integración con otras herramientas pueden variar según la complejidad.
Conclusiones finales
tanto Hive como Impala tienen sus ventajas y desventajas. La elección entre estas dos herramientas dependerá de las necesidades específicas de cada empresa. Hive es ideal para análisis detallados y complejos, mientras que Impala se destaca en la ejecución de consultas rápidas y en tiempo real. Al considerar factores como el rendimiento, la facilidad de uso, la integración y los costos, las empresas pueden tomar decisiones informadas sobre cuál de estas herramientas se adapta mejor a su estrategia de análisis de datos.