En Java, el manejo de datos es fundamental para desarrollar aplicaciones eficientes y funcionales. Dentro de este contexto, uno de los conceptos clave es la diferencia entre un flujo de bytes y un flujo de caracteres. Ambos tipos de flujos se utilizan para leer y escribir datos, pero cada uno tiene sus propias características y usos específicos. Comprender estas diferencias es esencial para elegir el tipo de flujo adecuado según las necesidades del programa que se esté desarrollando. A continuación, se explorarán en detalle las características de cada tipo de flujo y sus aplicaciones.
¿Qué es un flujo de bytes?
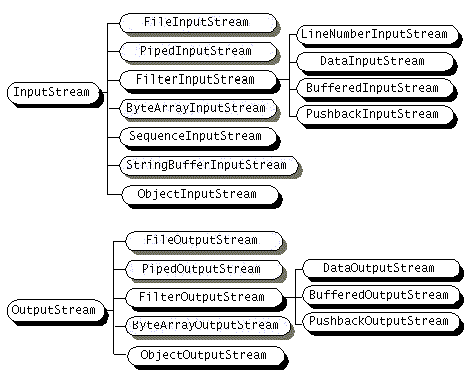
Un flujo de bytes es una secuencia de datos que representa información en forma de bytes. Este tipo de flujo es utilizado principalmente para trabajar con datos binarios, como imágenes, audio y otros tipos de archivos que no son texto. Los flujos de bytes en Java son parte de la biblioteca de entrada/salida (I/O) y se utilizan a través de clases como InputStream y OutputStream. Estas clases permiten leer y escribir datos en forma de bytes, lo que resulta esencial para manejar archivos que no son estrictamente textuales.
Los flujos de bytes son especialmente útiles cuando se necesita manipular datos en su forma original, como al leer un archivo de imagen o un archivo de audio. Por ejemplo, al utilizar un flujo de bytes para leer una imagen, se puede acceder a todos los datos de la imagen sin preocuparse por la codificación de caracteres. Esto permite que el programa procese la imagen tal como es, lo que resulta en un manejo más eficiente y directo de los datos.
Diferencia entre un gráfico dirigido y no dirigidoVentajas de los flujos de bytes
- Flexibilidad: Los flujos de bytes pueden manejar cualquier tipo de dato binario, lo que los hace muy versátiles.
- Rendimiento: La lectura y escritura de datos en forma de bytes suele ser más rápida que en forma de caracteres, especialmente para archivos grandes.
- Compatibilidad: Son ideales para trabajar con archivos que no son de texto, como imágenes y videos.
Además de las ventajas mencionadas, los flujos de bytes son esenciales en situaciones donde se requiere un control preciso sobre los datos. Por ejemplo, al trabajar con archivos de audio, se necesita acceder a los datos en su forma original para poder procesarlos adecuadamente. De esta manera, los flujos de bytes permiten una mayor libertad en la manipulación de datos, lo que es fundamental en muchas aplicaciones modernas.
¿Qué es un flujo de caracteres?
Por otro lado, un flujo de caracteres es una secuencia de datos que representa información en forma de caracteres. Este tipo de flujo es utilizado principalmente para trabajar con texto, y es fundamental para aplicaciones que requieren la manipulación de cadenas de caracteres. En Java, los flujos de caracteres se manejan a través de clases como Reader y Writer, que permiten leer y escribir datos en forma de caracteres, utilizando codificaciones específicas como UTF-8 o ASCII.
Los flujos de caracteres son especialmente útiles cuando se trabaja con archivos de texto, como documentos o archivos de configuración. Al utilizar un flujo de caracteres, el programador no tiene que preocuparse por la conversión de bytes a caracteres, ya que estas clases manejan automáticamente la codificación. Esto simplifica el proceso de lectura y escritura de texto, haciendo que sea más fácil y menos propenso a errores.
Diferencia entre un hacker y un crackerVentajas de los flujos de caracteres
- Simplicidad: Los flujos de caracteres son más fáciles de usar para trabajar con texto, ya que manejan automáticamente la codificación.
- Legibilidad: Al trabajar con texto, los datos son más comprensibles y fáciles de manipular.
- Integración: Se integran bien con otras bibliotecas y herramientas que trabajan con texto.
Las ventajas de los flujos de caracteres se hacen evidentes en aplicaciones que requieren la manipulación de datos textuales, como procesadores de texto o aplicaciones de análisis de datos. La capacidad de trabajar directamente con caracteres facilita la implementación de funciones como la búsqueda y el reemplazo de texto, así como la validación de entradas de usuario. Esto es especialmente importante en el desarrollo de aplicaciones que interactúan con los usuarios, donde la legibilidad y la facilidad de uso son cruciales.
Diferencias clave entre flujos de bytes y flujos de caracteres
Una de las diferencias más importantes entre los flujos de bytes y los flujos de caracteres es la forma en que manejan los datos. Mientras que los flujos de bytes trabajan directamente con datos binarios, los flujos de caracteres convierten esos datos en caracteres utilizando una codificación específica. Esta diferencia es fundamental y afecta cómo se utilizan los flujos en diferentes situaciones. Por ejemplo, al leer un archivo de texto con un flujo de bytes, se obtienen datos en forma de bytes, lo que requeriría una conversión adicional para ser interpretados como texto.
Otra diferencia significativa es el rendimiento. Los flujos de bytes suelen ser más rápidos para leer y escribir datos, especialmente en el caso de archivos grandes. Esto se debe a que los flujos de bytes operan a un nivel más bajo, lo que permite un acceso más directo a los datos. En contraste, los flujos de caracteres pueden introducir cierta sobrecarga debido a la necesidad de convertir entre bytes y caracteres, lo que puede afectar el rendimiento en aplicaciones que requieren una alta eficiencia.
 Diferencia entre Maven y Gradle
Diferencia entre Maven y GradleResumen de diferencias
- Tipo de datos: Los flujos de bytes manejan datos binarios, mientras que los flujos de caracteres manejan texto.
- Codificación: Los flujos de caracteres utilizan codificaciones para convertir bytes en caracteres, lo que no ocurre en los flujos de bytes.
- Rendimiento: Los flujos de bytes suelen ser más rápidos que los flujos de caracteres en la lectura y escritura de datos.
Estas diferencias hacen que cada tipo de flujo sea adecuado para situaciones específicas. Por ejemplo, si se está desarrollando una aplicación que necesita manipular imágenes o archivos de audio, un flujo de bytes sería la mejor opción. Por otro lado, si se está trabajando en una aplicación que requiere la manipulación de texto, como un editor de texto, un flujo de caracteres sería más apropiado. Al entender estas diferencias, los desarrolladores pueden tomar decisiones más informadas sobre qué tipo de flujo utilizar en sus aplicaciones.
Cuándo usar flujos de bytes y cuándo usar flujos de caracteres
La elección entre un flujo de bytes y un flujo de caracteres depende en gran medida del tipo de datos que se esté manejando. Si el objetivo es trabajar con datos binarios, como imágenes, videos o archivos comprimidos, entonces se debe optar por un flujo de bytes. Este tipo de flujo permite un manejo más eficiente de los datos, ya que no se requiere ninguna conversión adicional. Por ejemplo, al cargar una imagen desde un archivo, es esencial utilizar un flujo de bytes para garantizar que se obtengan todos los datos de la imagen sin pérdida de información.
Por otro lado, si se está trabajando con datos textuales, como archivos de texto, documentos o entradas de usuario, se debe utilizar un flujo de caracteres. Este tipo de flujo simplifica el proceso de lectura y escritura de texto, ya que se encarga automáticamente de la codificación y la conversión de bytes a caracteres. Esto es especialmente útil en aplicaciones donde la interacción con el usuario es clave, como en formularios web o editores de texto. Utilizar un flujo de caracteres en estos casos no solo mejora la eficiencia, sino que también reduce la posibilidad de errores relacionados con la codificación.
Ejemplos de uso
- Flujos de bytes: Cargar y guardar imágenes, trabajar con archivos de audio, manipular archivos binarios.
- Flujos de caracteres: Leer y escribir archivos de texto, procesar datos de formularios, manejar cadenas de caracteres.
Al final, la elección entre un flujo de bytes y un flujo de caracteres no es solo una cuestión de preferencia, sino que debe basarse en las necesidades específicas de la aplicación que se está desarrollando. Al entender las características y ventajas de cada tipo de flujo, los desarrolladores pueden optimizar sus aplicaciones y garantizar que manejan los datos de la manera más eficiente posible.
Consideraciones al trabajar con flujos de bytes y caracteres
Cuando se trabaja con flujos de bytes y caracteres, es importante tener en cuenta ciertas consideraciones que pueden afectar el funcionamiento de la aplicación. Una de las consideraciones más relevantes es la codificación. Al utilizar flujos de caracteres, es fundamental especificar la codificación adecuada para garantizar que los datos se interpreten correctamente. Por ejemplo, si se está leyendo un archivo que utiliza la codificación UTF-8, se debe indicar esta codificación al crear el flujo de caracteres. De lo contrario, los caracteres pueden no ser representados correctamente, lo que puede llevar a errores en la aplicación.
Otra consideración importante es el manejo de excepciones. Al trabajar con flujos de entrada y salida, es probable que se presenten excepciones relacionadas con la lectura y escritura de datos. Es esencial implementar un manejo adecuado de excepciones para garantizar que la aplicación pueda manejar errores de manera efectiva. Esto incluye el uso de bloques try-catch para capturar excepciones y tomar las acciones necesarias, como cerrar los flujos o notificar al usuario sobre el error.
Mejores prácticas
- Especificar la codificación: Siempre indique la codificación al trabajar con flujos de caracteres.
- Manejo de excepciones: Implemente bloques try-catch para manejar errores de manera efectiva.
- Cierre de flujos: Asegúrese de cerrar los flujos después de su uso para liberar recursos.
Finalmente, es importante recordar que la elección del tipo de flujo no solo afecta el rendimiento, sino también la calidad y la robustez de la aplicación. Al seguir las mejores prácticas y considerar las necesidades específicas de los datos que se están manipulando, los desarrolladores pueden crear aplicaciones más eficientes y confiables.
Ejemplos prácticos en Java
Para ilustrar mejor la diferencia entre flujos de bytes y flujos de caracteres, a continuación se presentan ejemplos prácticos de cómo utilizar ambos tipos de flujos en Java. Estos ejemplos ayudarán a entender cómo se implementan en la práctica y cómo se pueden aplicar en diferentes situaciones.
Ejemplo de flujo de bytes
A continuación, se presenta un ejemplo simple de cómo leer un archivo de imagen utilizando un flujo de bytes. Este código utiliza la clase FileInputStream para abrir el archivo y leer los datos en forma de bytes:
import java.io.FileInputStream;
import java.io.IOException;
public class LeerImagen {
public static void main(String[] args) {
String rutaArchivo = «imagen.jpg»;
FileInputStream flujoDeBytes = null;
try {
flujoDeBytes = new FileInputStream(rutaArchivo);
int dato;
while ((dato = flujoDeBytes.read()) != -1) {
// Procesar el dato de la imagen
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (flujoDeBytes != null) {
try {
flujoDeBytes.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
En este ejemplo, se abre un archivo de imagen llamado «imagen.jpg» y se leen los datos en forma de bytes. El bucle while continúa leyendo hasta que no quedan más datos. Es importante cerrar el flujo al final para liberar los recursos utilizados.
Ejemplo de flujo de caracteres
A continuación, se presenta un ejemplo de cómo leer un archivo de texto utilizando un flujo de caracteres. Este código utiliza la clase FileReader para abrir el archivo y leer los datos en forma de caracteres:
import java.io.FileReader;
import java.io.BufferedReader;
import java.io.IOException;
public class LeerTexto {
public static void main(String[] args) {
String rutaArchivo = «texto.txt»;
BufferedReader flujoDeCaracteres = null;
try {
flujoDeCaracteres = new BufferedReader(new FileReader(rutaArchivo));
String linea;
while ((linea = flujoDeCaracteres.readLine()) != null) {
System.out.println(linea);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (flujoDeCaracteres != null) {
try {
flujoDeCaracteres.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
En este ejemplo, se abre un archivo de texto llamado «texto.txt» y se leen las líneas del archivo utilizando un BufferedReader. Este enfoque es más eficiente para leer texto, ya que permite leer líneas completas de una sola vez. Al igual que en el ejemplo anterior, es importante cerrar el flujo al final para liberar los recursos utilizados.
Conclusiones sobre el uso de flujos en Java
Al final, la elección entre un flujo de bytes y un flujo de caracteres en Java depende de las necesidades específicas de la aplicación y del tipo de datos que se estén manipulando. Comprender las diferencias clave entre ambos tipos de flujos es fundamental para desarrollar aplicaciones eficientes y efectivas. Al seguir las mejores prácticas y considerar las características de cada tipo de flujo, los desarrolladores pueden optimizar sus aplicaciones y garantizar que manejan los datos de la manera más adecuada posible.
En resumen, al trabajar con flujos en Java, es esencial tener en cuenta la naturaleza de los datos, la codificación y el rendimiento. Esto permitirá a los desarrolladores tomar decisiones informadas y crear aplicaciones que sean no solo funcionales, sino también eficientes y confiables.